JDK12
面向对象
函数式编程
JVM: Java Virtual Machine
虚拟的用于执行bytecode字节码的计算机
JDK: Java Development Kit
JRE: Java Runtime Environment
安装与配置环境变量
安装包地址
链接:https://pan.baidu.com/s/19j-EKoXEQP_BnWTcu1fmiw
提取码:9ys5
JDK12安装完成后不再自动生成
jre文件夹,需要在JDK12安装目录下自行运行命令生成命令行输入:
bin\jlink.exe --module-path jmods --add-modules java.desktop --output jreJDK 9版本之前类和资源文件存储在
lib/rt.jar、tools.jar中,JDK 9版本开始lib/dt.jar和其他各种内部JAR文件都存储在一个更有效的格式在实现特定的文件lib目录。
因此CLASS PATH变量中不再需要配置lib/rt.jar、tools.jar
网络编程-IP、TCP、UDP
基本概念
网络: 一组相互连接的计算机
多台计算机组成
使用物理线路进行连接
网络编程三要素
IP地址: 唯一标识网络上的每一台计算机
两台计算机之间通信的必备要素
端口号: 计算机中应用的标号(代表一个应用程序)
0-1024系统使用或保留端口
有效端口0-65536
通信协议: 通信的规则
TCP,UDP
网络模型
OSI参考模式: 开放系统互连参考模型(Open System Interconnect)
TCP/IP参考模型: 传输控制/网际协议 (Transfer Control Protocol/Internet Protocol)
OSI为逻辑上的参考模式,常用还是TCP/IP
IP地址
32位,由4个8位二进制数组成
表示方法: 点分十进制
IP地址 = 网络ID + 主机ID
网络ID: 标识计算机或网络设备所在的网段
主机ID:标识特定主机或网络设备
IP地址的分类
地址类用于指定网络ID并在网络ID和主机ID之间提供分隔方法
IANA负责分配A,B, C类网络地址,具体主机地址由机构组织自行分配
IP地址包括A、B、C、D、E类
A类地址供军方使用,范围: 1.0.0.0~126.0.0.0
B类地址供普通用户使用,范围: 128.0.0.0~1191.255.255.255
C类地址供普通用户使用,范围: 192.0.0.0~223.255.255.255
D类地址供广播地址或一些通用服务地址使用,范围: 224.0.0.0~239.255.255.255
E类地址范围: 240.0.0.0~247.255.255.255
特殊的IP地址
0.0.0.0: 本机,阻断与外网通信127.0.0.1: 本机回环地址(Local Loopback),用于本机测试255.255.255.255: 当前子网,一般用于向当前子网广播信息
IP地址对应的对象
类InetAddress
getLocalHost(): 获取本机主机名+IP地址
端口
端口是一个虚拟的概念,通过端口可以在一个主机上运行多个网络应用程序
传输协议
TCP
相当于打电话,需要建立连接,效率比较低,数据传输安全。
三次握手协议完成。
UDP
相当于发短信(有字数限制),不需要建立连接,数据包的大小限制在64k内,效率高,不安全,容易丢包
三次握手协议和四次分手协议
Socket
- 网络上的两个程序
基于TCP协议的Socket编程
创建客户端
new一个socket对象,开启实现IO的虚拟接口,发送数据
创建服务端
new一个serverSocket对象,开放端口
创建服务端的一个搜socket对象
UDP
UDP传输方式和TCP不同,UDP传输的是数据包
lambda表达式
介绍
JDK8中最重要的新功能之一。使用lambda表达式可以替代只有一个抽象函数的接口实现,告别匿名内部类,使代码看起来简单易懂。
Lambda表达式同时还提升了对集合、框架的迭代、遍历、过滤数据的操作
特点
函数式编程
参数类型自动推断
代码量少,简洁
应用场景
任何有函数式接口的地方
函数式接口
只有一个抽象方法(Object类中的方法除外)的接口是函数式接口
1 |
|
java提供了一系列的函数式接口,用于接收后续传入的参数,但是对输入和输出类型有要求
方法的引用
方法引用是用来直接访问类或实例的已经存在的方法或者构造方法,方法引用提供了一种引用而不执行方法的方式,如果抽象方法的实现恰好可以使用调用另外一个方法来实现,就有可能可以使用方法引用。
方法引用的分类
| 类型 | 语法 | 对应的Lambda表达式 |
|---|---|---|
| 静态方法引用 | 类名::staticMethod | (args) -> 类名.staticMethod(args) |
| 实例方法引用 | inst::instMethod | (args) -> inst.instMethod(args) |
| 对象方法引用 | 类名::instMethod | (inst.args) -> 类名.instMethod(args) |
| 构造方法引用 | 类名::new | (args) -> new 类名(args) |
Stream API
Stream是一组用来处理数组、集合的API
JDK8引入函数式编程原因:
代码简洁且意图明确,使用Stream接口让你从此告别for村换
多核友好
Stream特性
不是数据结构,没有内部储存
不支持索引访问
延迟计算
支持并行
很容易生成数组或集合(List, Set)
支持过滤、查找、转换、汇总、聚合等操作
Stream运行机制
Stream分为源source,中间操作,终止操作
流的源可以是一个数组、一个集合、一个生成器方法、一个I/O通道等等
一个留可以有零个和或者多个中间操作,每一个中间操作都会返回一个新的流供下一个操作使用。
一个流只会有一个终止操作。
Stream只有遇到终止操作,它的源才开始执行遍历操作
if 语句
三元运算符与if语句
三元运算符能实现的都可采用if语句实现,反之不成立。因为三元运算符不能执行输出语句。
若只需赋值,可用三元运算符简化代码。
switch语句
switch表达式可接收类型
- 基本数据类型可以接收byte,short,char,int
- 引用数据类型可以接收枚举(JDK1.5) String类型(JDK1.7)
swith语句注意事项
- case后面只能是常量,不能是变量。多个case的值不能相同
- 每个case后面都要加break,否则会出现case穿透
- default可以放在任何位置,但建议放最后
if语句和switch语句的各自使用场景
switch在判断固定值时使用,if建议判断区间和范围时使用
for语句、while语句和do while语句
三者区别
- do while 先执行循环体再判断,至少会执行一次循环体
- for语句执行后,变量会被释放,不能再使用;while执行后,初始化变量还能继续使用
如果想在循环结束后继续使用控制条件的变量,用while语句,否则尽量用for循环,以提高内存的使用效率
无限循环语句
while语句无限循环:1
2
3while(true) {
System.out.println("This is a loop");
}
for语句的无限循环:1
2
3for(; ;) {
System.out.println("This is a loop");
}
转义字符
\x x表示任意,\是转义符号,这种做法叫转义字符
\t表示tab键(制表符)\r表示回车\n表示换行\"表示转义双引号\'表示转义单引号
方法的概述和格式说明
1 | /** |
方法的注意事项
- 方法不调用不执行
- 方法与方法是平级关系,不能嵌套定义
- 方法定义的时候参数之间用逗号隔开
方法的重载
重载: 方法名相同,参数列表不同,与返回值类型无关
重载的分类:
- 参数的个数不同
- 参数的类型不同
- 参数的顺序不同
数组
同时存储同一种数据类型多个元素的集合,既可存储基本数据类型,也可存储引用数据类型。
格式: 数据类型[] 数组名 = new 数据类型[数组的长度]
数组的初始化
动态初始化
数据类型[] 数组名 = new 数据类型[数组的长度]
e.g: int[] arr = new int[5]
相当于在内存中开辟5个连续的储存空间
java中的内存分配以及栈和堆的区别
栈: 存储局部变量(定义在方法声明上和方法中的变量),每个方法是一个栈针形式
堆: 存储new出来的数组或对象
方法区:
本地方法区: 和系统相关
寄存器: 给CPU用
静态初始化
格式: 数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, ...}
简化格式: 数据类型[] 数组名 = {元素1, 元素2, ...}
简化格式的声明和赋值只能在同一行,否则编译不通过。
参数传递问题
基本数据类型的值传递,不改变原值,因为调用后会弹栈,局部变量随之消失
引用数据类型的值传递,改变原值,因为即使方法弹栈,但是堆内存数组对象还在,可以通过地址继续访问
java中只有传值,因为地址值也是值
构造方法、static关键字 (day 07)
构造方法特点
- 方法名和类名相同
- 没有返回值类型,连void也没有
- 没有具体的返回值,直接return
- 若无构造方法,系统会自动提供一个无参的构造方法
若有有参构造方法,则必须自己写一个无参的构造方法
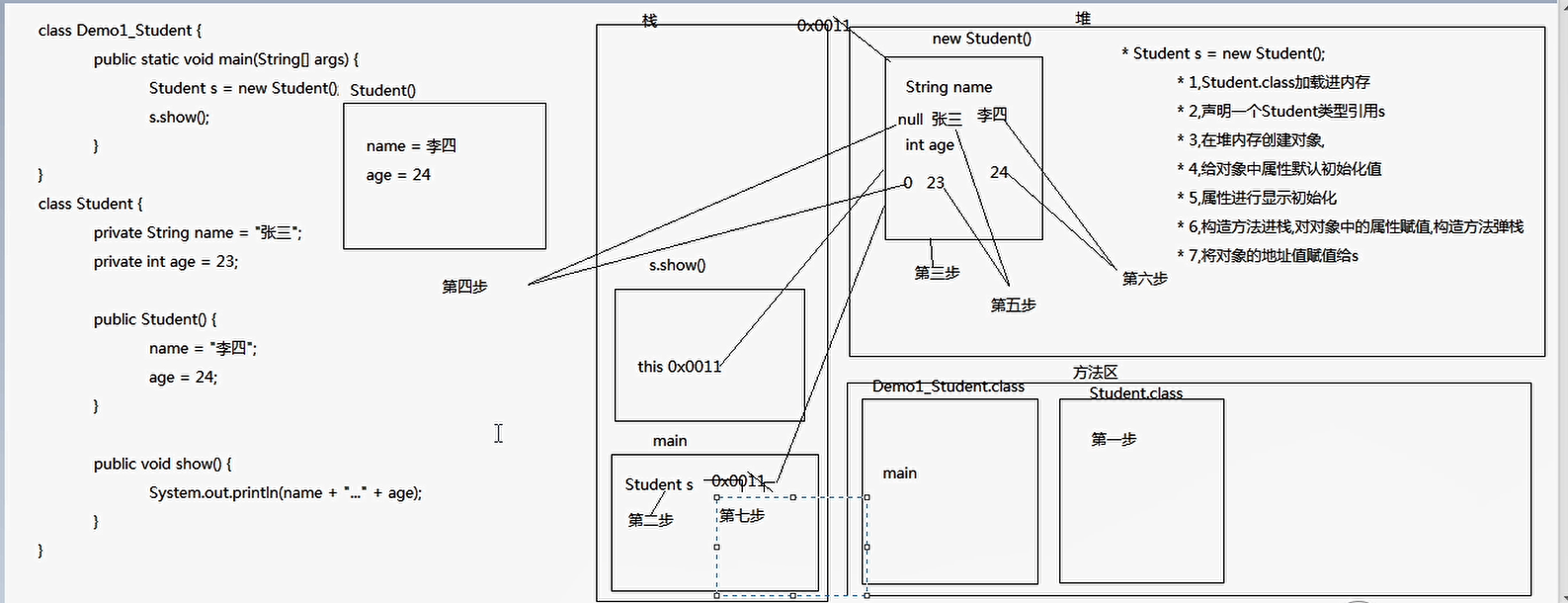
创建对象的步骤
- Student.class加载进内存
- 声明一个Student类型引用s
- 在堆内存创建对象
- 给对象中属性默认初始化值
- 属性进行显示初始化
- 构造方法进栈,对对象中的属性赋值,构造方法弹栈
- 将对象的地址赋值给s
static关键字及内存图(day07 07.09)
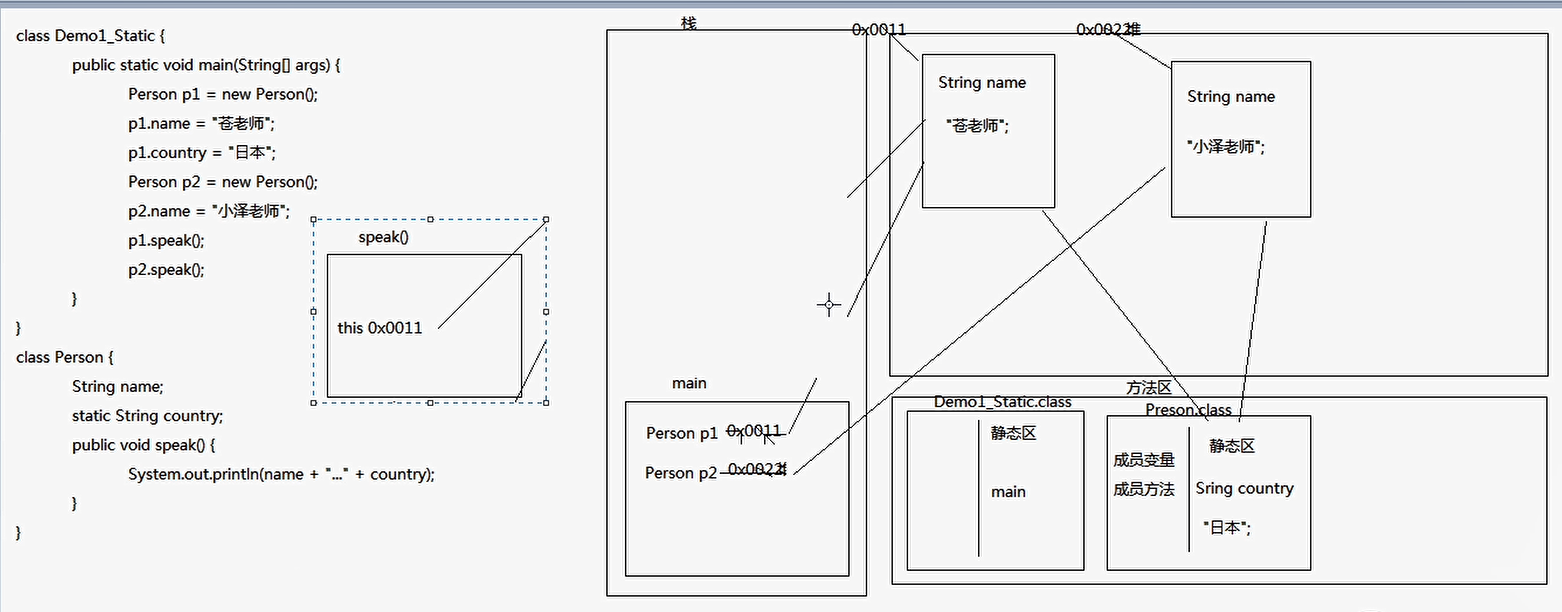
static关键字的特点
- 随着类的加载而加载
- 优先于对象存在
- 被类的所有对象共享
当某个成员变量是被所有对象所共享,那么它就应该送一位静态的 - 可以通过类名调用,推荐使用类名调用;静态修饰的内容,一般我们称其为与类相关的,类成员
static的注意事项
a. 在静态方法中是没有this关键字的,因为静态是随着累的加载而加载,优先于对象的存在,而this是随着对象的创建而存在的
b. 静态方法只能访问静态的成员变量和静态的成员方法
静态变量和成员变量的区别
a. 所属不同
* 静态变量属于类,所以也称为类变量
* 成员变量属于对象,所以也称为实例变量(对象变量)
b. 内存中的位置不同
* 静态变量存储于方法区的静态区
* 成员变量存储于堆内存
c. 内存出现时间不同
* 静态变量随着类的加载而加载,随着类的消失而消失
* 成员变量随着对象的创建而存在,随着对象的消失而消失
d. 调用不同
* 静态变量可以通过类名调用,也可以通过对象调用
* 成员变量只能通过对象名调用
main方法的格式和详细解释
public : 被jvm调用,所以需要权限足够大
static : 被jvm调用,不需要创建对象,直接类名.调用即可
void : 被jvm调用,不需要有任何的返回值
main : 只有这样写才能被jvm识别,main不是关键字
String[] args : 以前用来接收启动时的键盘录入,现在用System.Scanner(System.in)来接收键盘录入
![main方法String[]](/data/img/javase/main方法String[].jpg)
工具类中使用静态
工具类中使用静态方法,可不用创建对象直接调用;若一个类中所有的方法都为静态方法,则需要将构造方法私有化,目的是不让其他类创建本类,直接用类名.方法调用即可
说明书的制作过程
- 使用多行注释在类和方法中进行注释,写明版本、作者、参数、返回值等信息
- 对需要生成api的文件进行javadoc命令
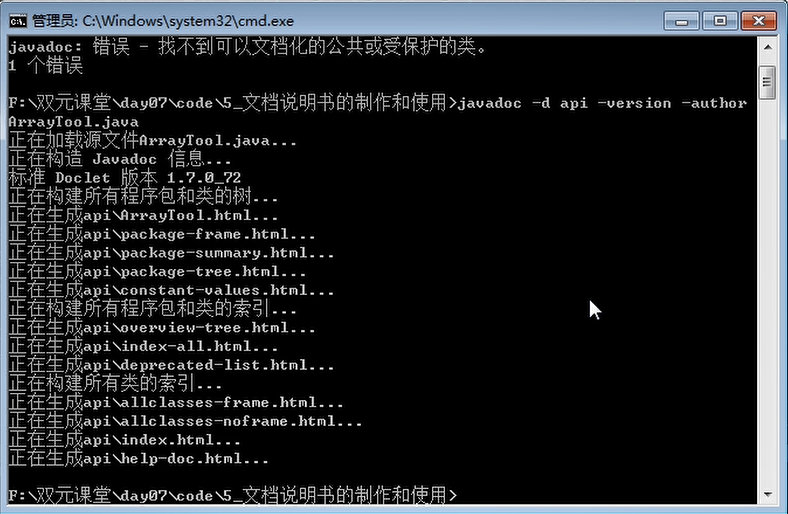
javadoc -d api -version -author ArrayTools.java
javadoc生成文档命令-d api文件生成保存路径-version版本-author作者ArrayTools.java源文件类的名字文件生成后,直接打开
index.html既可
代码块、继承、方法重写、final关键字(day 08)
代码块
java中使用{}括起来的代码称为代码块,分为局部代码块、构造代码块、静态代码块、同步代码块
- 局部代码块: 在方法中出现,限定变量的生命周期,及早释放,提高内存效率
- 构造代码块(初始化代码块):在类中方法外出现;多个构造方法中相同的代码存放到一起,每次调用构造都执行,并且在构造方法前执行
- 静态代码块: 在类中方法外出现,加了static修饰;用于给类进行初始化,在加载时执行,并且只执行一次,一般用于加载驱动
继承
关键字: extends
让类与类之间产生关系,子父类关系
好处:
- 提高代码的复用性
- 提高了代码的维护性
- 让类与类之间产生了关系,是多态的前提
弊端:- 增强类的耦合性
开发的原则: 高内聚,低耦合
- 耦合是指类与类的关系
内聚是指自己完成某件事情的能力
继承的特点
java只支持单继承不支持多继承,但支持多层继承(B extends A, C extends B)
继承的注意事项
- 子类只能继承父类所有非私有成员(成员方法和成员变量)
- 子类不能继承父类的构造方法,但是可以通过super关键字去访问父类构造方法
不要为了部分功能而去继承
this和super的区别
this.成员变量:既可以调用本类的成员变量,也可调用父类成员变量(本类无成员变量)super.成员变量: 调用父类成员变量继承中构造方法的关系
子类中所有的构造方法默认都会访问父类中空参数的构造方法。
每一个构造方法的第一条语句默认都是 super() Object类最顶层的父类继承中构造方法的注意事项
父类没有无参构造方法,子类只能通过super或者this来访问父类的有参构造方式。super和this不能共用,因为两者都必须放在构造器中的第一个语句。
方法的重写
子父类出现了一模一样的方法
子类可以重写父类中的方法,这样既沿袭了父类的功能,又定义了自己特有的功能方法重写的注意事项
- 父类的思想方法不能被重写
- 子类重写父类方法时,访问权限不能更低
- 父类静态方法,子类也必须通过静态方法重写(静态方法只能覆盖静态方法)
方法的重载(overload)和重写(overload)
方法重写: 子父类出现一模一样的方法,与返回值类型有关,返回值是一致的
方法重载: 在本类中出现的方法名一样,参数列表不同,与返回值无关
final关键字
特点
- 修饰类,类不能被继承
- 修饰变量, 变量变为常量,只能被赋值一次
- 修饰方法, 方法不能被重写
final修饰基本数据类型,值不能被改变;
final修饰引用数据类型,地址值不能被改变,但对象中的属性可以改变。
成员变量的从默认初始化值是无效值,因此final修饰的成员变量初始化时需要赋值或者利用构造方法初始化。
多态、抽象类
多态
多态的前提
- 要有继承关系
- 要有方法重写
- 要有父类引用指向子类方法
多态中的成员访问特点
成员变量
编译看左边(父类),运行看左边(父类)
成员方法
编译看左边(父类),运行看右边(子类) (动态绑定)
静态方法
编译看左边(父类),运行看左边(父类)
向上转型和向下转型
引用数据类型会先向上转型,才能向下转型。
好处和弊端
好处:
- 提高代码的可维护性
- 提高代码的扩展性
弊端:
- 不能使用子类的特有属性和行为
多态一般用于当做参数,因为其拓展性强
抽象类
特点
关键字abstract修饰
- 抽象类不一定有抽象方法,有抽象方法的类一定是抽象类或接口
- 抽象类不能实例化,只能通过子类实例化
- 抽象的子类只能是抽象类或重写抽象类的所有方法
成员特点
- 成员变量既可以是变量也可以是常量。
- 有构造方法,便于子类访问父类数据的初始化
- 成员方法,既可以是抽象也可以是非抽象(非抽象需要重写父类所有方法)
面试题
- 一个抽象类如果没有抽象方法,可以定义为抽象类,这样做是为了不让其他类创建本类的对象,只能通过此抽象的子类实例化
abstract不能和那些关键字共存
static被
abstract修饰的方法没有方法体,被static修饰的可以用类名.调用,调用抽象方法是没有意义的final被
abstract修饰的方法强制子类重写,被final修饰的不让子类重写private被
abstract修饰的是为了让子类看到并强制重写,被private修饰不让子类访问
接口(interface)
- 使用关键字
interface表示,接口中的方法都是抽象的。 - 类实现接口用
implement表示:class 类名 implement 接口名 {} - 接口不能实例化
- 接口的子类可以是抽象类,也可以是具体类,但是具体类需要重写接口中的所有抽象方法
接口的成员特点
- 成员变量: 只能是常量,并且是静态、公共的,默认修饰符:
public static final,建议手动给出 - 构造方法: 接口没有构造方法
- 成员方法: 只能是抽象方法,默认修饰符:
public abstract,建议手动给出
类与类、类与接口、接口与接口的关系
类与类: 继承关系,只能是单继承,可以多层继承
类与接口: 实现关系,可以单实现,也可以多实现并且能在继承一个类的同时实现多个接口
接口与接口: 继承关系,可以是单继承,也可以是多继承
抽象类和接口的区别
成员区别:
- 成员变量: 抽象类的可以是变量,也可以是常量;接口的只能是常量
- 构造方法: 抽象类有构造方法,接口无
- 成员方法: 抽象类的可以是抽象方法,也可以是非抽象;接口的只可以是抽象
设计理念区别:
- 抽象类被继承,体现的是
is a的关系,抽象类定义的是该继承体系的共性功能 - 接口,被实现的是
like a的关系,接口中定义的是该继承体系的扩展功能
day10
四种权限修饰符
public、defalut、 protected、 private
private只能在本类中访问default默认不写,能在本类和同包下访问protected在不同包下的无关类无法访问public均能访问
状态修饰符: static、 final
局部内部类
方法中的内部类;
局部内部类访问局部变量,局部变量需要用final修饰。(JDK 1.8中取消了此事)
匿名内部类
匿名内部类只针对重写一个方法的时候使用。匿名内部类当做参数传递,本职是把匿名内部类看做一个对象。
链式编程,调用方法后还能继续调用方法,证明调用方法后返回的是一个对象
eclipse、Object类
eclipse快捷键
alt + / 提示代码ctrl + n 新建ctrl + shift +f 格式化ctrl + shif +o 整理包ctrl + /单行注释ctrl+shift+/ 多行注释ctrl + shift +\alt + 上下箭头 上下移动代码F3或按住ctrl点击类名可以查看源码ctrl + shift + t 查找具体的类ctrl + o查找具体类的具体方法ctrl + d 删除代码ctrl + shift + m 抽取方法alt + shift + r 改名alt + shift + s 快速生成getter、setter等方法ctrl + alt + 上下键 向上/下复制一行代码
打jar包
选中项目–>右键–>Export–>java–>Jar–>指定路径和名称–>finish
导入jar包
选中jar包–>右键–>build path
Object类
hashcode()方法: 返回对象的地址值。
getClass()方法: 返回对象的class文件。
toString()方法: 更方便的显示属性值。如果直接打印对象的引用,会默认调用toString方法。
equals方法: 判断两个对象是否相等(比较的是地址值),返回布尔值。Object的equals方法比较的是地址值,因此开发中没什么意义,一般都要重写此方法,重写后一般比较的是对象中的属性值。
== 和equals的区别
共同点: 都可以做比较,返回值都是布尔值
区别:
==是比较运算符,即可以比较基本数据类型,也可以比较引用数据类型。基本数据类型比较的是值,引用数据类型比较的是地址值equals方法只能比较引用数据类型,equals方法在没重写之前比较的是地址值,底层依赖的是==号,但是比较地址值是没有意义的,需要重写equals方法比较对象中的属性值
Scanner、String 类(day 12)
Scanner类
一般方法:
hasNextXXX() 判断是否有下一个输入项,XXX可以是Int double等
nextXxx() 获取下一个输入项,nextLine()用于获取一个String类型的值
nextLine()遇到键盘输入的/r/n时会自动停止,获取键盘输入自动会有/r/n
String类
字符串是常量,一旦被赋值就不能被改变
常见构造方法
- 空构造 String()
- 把字节数组转成字符串 String(byte[] bytes)
- 把字节数组的一部分转成字符串 Sting(byte[] bytes, int index, int length)
- 把字符数组转成字符串 String(char[] value)
- 把字符数组的一部分转成字符串 String(char[] value, int index, int length)
- 把字符串常量值转成字符串 String(String original)
常见面试题
常量池中若无某字符串对象,则创建一个,如有则直接使用1
2
3String s1 = new String("abc"); // 记录的是堆里面的地址值
String s2 = "abc";// 记录的是常量池里的地址值
s1 == s2;// false
String类的判断功能
- 比较字符串的内容是否相同,区分大小写: equals(Object obj)
- 比较字符串的内容是否相同,忽略大小写: equalsIgnoreCase(String str)
- 判断大字符串是否包含小字符串: contains(String str)
- 判断字符串是否以某个指定的字符串开头: startsWith(String str)
- 判断字符串是否以某个指定的字符串结尾: endsWith(String str)
- 判断是否为空: isEmpty()
String类的获取功能
- 获取字符串的长度: int length();
- 获取指定索引位置的字符: char charAt(int index)
- 返回指定字符在此字符串中第一次出现处的索引: int indexOf(int ch)
- 返回指定字符串在此字符串中第一次出现处的索引: int indexOf(String str)
- 返回指定字符在此字符串中从指定位置后第一次出现处的索引: int indexOf(int ch, int fromIndex)
- 返回指定字符串在此字符串中从指定位置后第一次出现处的索引: int indexOf(String str, int fromIndex)
- 从后向前找,第一次出现指定字符的索引: lastIndexOf
- 从指定位置开始截取字符串,默认到末尾 String substring(int start) (substring会产生新的字符串)
- 从指定位置开始到指定位置结束截取字符串 String substring(int start, int end)
String类的转换功能
valueOf(Object obj); 将对象转为String
toLowerCase(): 把字符串转小写(返回新的字符串)
toUpperCase(): 把字符串转成大写(返回新的字符串)
concat(String str): 把字符串拼接
StringBuffer & 数组排序 (Day13)
StringBuffer
构造方法
- 无参构造方法
1 | StringBuffer sb = new StringBuffer(); |
- 指定容量
1 | StringBuffer sb2 = new StringBuffer(10); |
- 指定字符串
1 | StringBuffer sb3 = new StringBuffer("test"); |
添加功能
StringBuffer是字符串缓冲区,当new的时候,是在堆内存创建一个对象,底层是一个长度为16的字符数组,当调用添加方法时,不会再重新创建对象,在不断向原缓冲区添加字符;
StringBuffer类中重写了toString方法
1 | /** |
删除功能
当缓冲区中无索引时,报字符串越界异常
1 | /** |
替换和反转
StringBuffer replace(int start, int end, String str);
StringBuffer reverse();
字符串的反转:
- 将字符串转换成StringBuffer对象
StringBuffer sb = new StringBuffer(Str); - 使用reverse()方法反转
sb.reverse(); - 将StringBuffer对象转换成String
sb.tostring();
截取
String substring(int start);
String substring(int start, int end);
注: 截取返回值不再是StringBuffer本身,而是String
StringBuffer和String的转换
- String转StringBuffer
- 通过构造方法
StringBuffer sb = new StringBuffer(“XXX”); - 通过append()方法
StringBuffer sb2 = new StringBuffer();
sb2.append(“XXX”);
- StringBuffer转String
- 通过构造方法
StringBuffer sb = new StringBuffer(“XXX”);
String s1 = new String(sb); - 通过toString()方法
String s2 = sb.toString(); - 通过substring截取
String s3 = sb.substring(0, sb.length());
String和StringBuffer作为参数传递
基本数据类型的值传递,不改变其值;
引用数据类型的值传递,改变其值;
String类虽然是引用数据类型,但是它作为参数传递时和基本数据类型是一样的,一旦被初始化,就不会被改变
StringBuilder
StringBuffer和StringBuilder类中的方法是一样的
StringBuffer是JDK1.0版本的,线程安全,效率低;
StringBuilder是JDK1.5版本的,线程不安全,效率高;
String是一个不可变的字符序列,StringBuffer和StringBuilder是可变的字符序列
数组
数组转成字符串
遍历时用StringBuffer接收,减少创建对象次数。1
2
3
4
5
6
7
8
9
10
11
12
13
14public static String arrayToString(int[] arr) {
StringBuffer sb = new StringBuffer();
sb.append("[");
for(int i=0; i<arr.length; i++) {
if(i == arr.length - 1) {
// 若写成sb.append(arr[i] + ", "), 在运行+的命令时,会在底层创建StringBuffer对象
sb.append(arr[i].append("]"));
}else {
sb.append(arr[i].append(", "));
}
}
return sb.toString();
}
数组冒泡排序
冒泡排序: 轻的上浮,沉的下降
原理: 两个相邻位置比较,如果前面的元素比后面的元素大,就换位置
代码思路: 使用嵌套循环,外层循环arr.length-1次,内循环arr.length-1-i次
选择排序
选择排序: 用一个索引位置上的元素,依次与其他索引位置上的元素比较,小在前面,大在后面
二分查找
前提: 数组有序
二分查找: 查找元素对应的索引
Arrays类的概述和方法使用
- 数组转字符串
Arrays.toString(arr); - 数组排序
Arrays.sort(arr); - 二分查找
Arrays.binarySearch(arr);// 此处的arr为已排序数组,若无所查值,返回负的插入点-1
Integer和String类型的相互转换
- int转String
- String.valueof
- toString
- int值+””
- int转换为Integer类,再调用Integer.toString()
String转int
- Integer.parseInt(str);// 推荐使用
基本数据类型包装类有八种,其中七种都有parseXxx的方法,可以将这七种字符串表现形式转换成基本数据类型;char的包装类Character中没有parseXXX的方法
自动装箱和拆箱
自动装箱: 把基本数据类型转换成对象
Integer i = 100;
自动拆箱: 把对象转换为基本数据类型
int z = i + 200;
注: Integer为null时,会出现空指针异常Integer类相关
byte的取值范围为-128~127:
- 若在此取值范围内,自动装箱不会新创建对象,而是从常量池中获取
- 若超过byte的取值范围,自动装箱会创建新对象
1
2
3
4
5
6
7
8
9Integer i1 = 127;
Integer i2 = 127;
i1 == i2;// true
i1.equals(i2);// true
Integer i3 = 128;
Integer i4 = 128;
i3 == i4;// false
i3.equals(i4);// true
正则表达式(day 14)
正则表达式
一个用来描述或者匹配一系列符合某个语法规则的字符串的单个字符串
字符类
[abc]: []代表单个字符; 只能输入a、b或c[^abc]: 代表除a、b、c以外的所有单个字符[a-zA-Z]: a~z或A~Z,两头的字母包括在内[a-d[m-p]]: a到d或m到p:[a-dm-p](并集)[a-z&&[def]]: d、e或f (交集)[a-z&&[^bc]]: a到z,除了b和c:[ad-z](减去)[a-z&&[^m-p]]: a到z,而非m到p:[a-lq-z](减去)
预定义字符
.: 任何字符,转义时需要写成\\.\d: 数字:[0-9](\代表转义字符,如果想表示\d的话,需要写成\\d)\D: 非数字:[^0-9]\s: 空白字符:[\t\n\x0B\f\r]\S: 非空白字符:[^\s]\w: 单词字符:[a-zA-Z_0-9]\W: 非单词字符:[^\w]
数量词
X?: X一次或一次也没有(e.g.:[abc]?a、b、c出现1次或1次也没有)X*: X, 0次到多次X+: X, 1次或多次X{n}: X,恰好n次X{n,}: X, 至少n次X{n,m}: X, 至少n次,但是不超过m次
分割功能
String.split(String regex);根据正则分割
分组功能
1 | // \\1代表第一组又出现一次,\\2代表第二组又出现一次 (.)表示一个任意字符为一组 |
Pattern和Matcher
1 | Pattern p = Pattern.compile("a*b");// 获取正则表达式 |
获取功能
- 获取字符串中的手机号码
1 | String s = "我的手机号码是18988888888,曾用过18987654321,还用过18812345678"; |
Math类
成员方法:abs(int a) : 取绝对值ceil(double): 向上取整,返回doublefloor(double): 向下取整,返回doublemax(int a, int b): 获取两者的最大值pow(double a, double b): a为底数,b为指数random(): 生成[0.0, 1.0)的随机小数round(float a): 四舍五入sqrt(double a): 开平方
System类
System.gc(); // 运行垃圾回收
System.exit(0);// 非0状态是异常中止,退出jvm
System.currentTimeMillis();// 获取1970年到当前时间的毫秒值
BigInteger类
可以让超过Integer范围内的数据进行运算
Date类(util包)
1970年1月1日为UNIX TIME的纪元时间1
2
3Date d1 = new Date();// 空参构造,代表当前时间
Date d2 = new Date(0);// 1970年1月1日8点,存在系统时间和本地时间的时差
d1.getTime();// 通过时间对象获取毫秒值
SimpleDateFormat类
DateFormat类的子类,抽象类,不能被实例化。1
2
3
4
5
6
7
8
9
10Date d = new Date();// 获取当前时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
sdf.format(d);// 格式化时间
/**
* 将时间字符串转换成日期对象
*/
String str = "2000年08月08日 08:08:08";
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
Date d1 = sdf1.parse(str);
时间毫秒值/1000/60/60/24 得到天数
Calendar类
1 | Calendar c = Calendar.getInstance(); |
Day15(Collection)
数组和集合的区别
- 数组既可以存储基本数据类型又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值;集合只能存储引用数据类型(对象),集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象。
- 数组长度是固定的,不能自动增长;集合的长度是可变的,可以根据元素的增长而增长
- 元素个数是固定的推荐用数组;元素个数不固定,推荐用集合;遵循此规则节约内存,集合底层是数组,但随着集合的自动增长,会把之前的数组作废掉,产生很多内存垃圾
集合继承体系
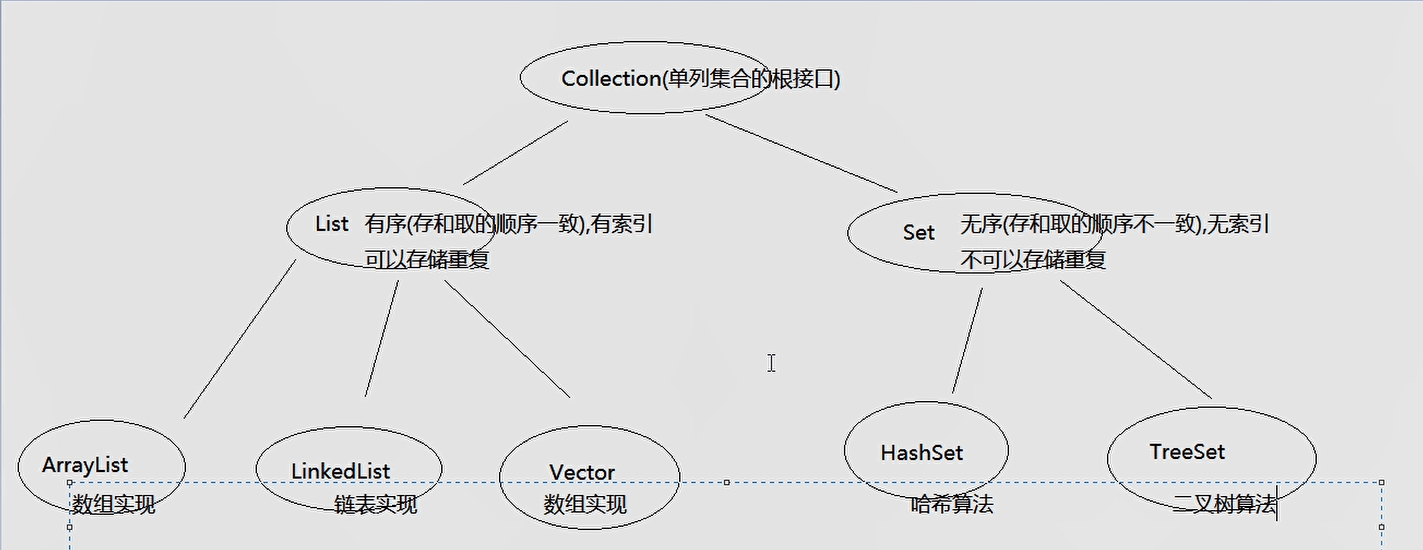
List集合中,add方法一定返回true,Set集合当存储重复元素时会返回false。
集合转数组遍历
toArray()方法,将集合转换成数组containsAll(Collection A),判断是否包含集合AretainAll(Collection A), 取与集合A的交集
迭代器原理
迭代器是对集合进行遍历,而每一个集合内部的存储结构是不同的,所以每一个集合存和取是不一样的,那么就需要在每一个类中定义hasNext()和next()方法,这样做是可以的,但会使整个集合体系过于臃肿,迭代器是将这样的方法向上抽取出接口,然后在每个类的内部定义自己迭代方法,这样做的好处有而,第一规定了整个集合体系的遍历方式都是hasNext()和next()方法,第二,代码有底层内部实现,使用者不用管怎么实现的,会用即可
List集合的特有功能
add(int index, E element)在指定位置添加元素;当存储时,出现不存在索引时,出现越界异常remove(int index)通过索引删除元素,将被删除的元素返回;删除时不会自动装箱get(int index)通过索引获取元素set(int index, E element)设置指定索引位置的值并发修改异常
遍历的同时在增加元素,出发并发修改异常。
解决方法:使用List特有的迭代器ListIterator,可在遍历时添加元素List三个子类的特点
- ArrayList: 底层数据结构是数组,查询快,增删慢,线程不安全,效率高
- Vector: 底层数据结构是数组,查询快,增删慢,线程安全,效率低
- LinkedList: 底层数据结构是链表,查询慢,增删快,线程不安全,效率高
综上,查询多时用ArrayList,增删多用LinkedList,如果都多,用ArrayList。
Day016 (List)
contains方法和remove方法,底层依赖的是equals方法
栈和队列数据结构
栈结构: 先进后出(类似纵向管道)
队列结构:先进先出(类似横向管道)
泛型generic
好处:
- 提高安全性(将运行期的错误转到编译期)
- 省去强转的麻烦
注意事项:
- 前后的泛型必须一致,或者后面的泛型可以省略不用写(1.7的新特性)
- 泛型不要定义为Object,没有意义
泛型通配符
<?>当右边泛型不确定时,左边可以用?? extends E向下限定,E及其子类? super E向上限定, E及其父类
增强for循环(foreach)
- 概述: 简化数组和Collection集合的遍历
- 格式:
for(元素数据类型 变量: 数组或Collection集合) {
}使用变量即可,该变量就是元素
增强for循环底层依赖的是迭代器Iterator
三种迭代的删除
- 普通for循环的删除,通过索引删除,索引要用
i-- - 迭代器删除,不能用集合的删除方法,会引发并发修改异常,只能用迭代器自带的remove方法。
- 增强for循环,不能删除,只能遍历
静态导入(开发中不常用)
概念: 导入类中的静态方法
格式: import static 包名···.类名.方法名
注意事项: 方法必须是静态的,如果有多个同名的静态方法,容易不知道使用谁,如果要使用,必须加前缀
可变参数
概述: 定义方法的时候不知道该定义多少个参数时使用可变参数
格式: 修饰符 返回值类型 方法名(数据类型… 变量名){}
注意事项:
- 可变参数其实是一个数组
- 如果一个方法有可变参数,并且有多个参数,那么可变参数肯定是最后一个
Arrays工具类
asList: 数组转换成集合1
2int[] arr = {11,22,33,44,55};
List<String> list = Arrays.asList(arr);
注:
- 数组用asList转为集合后,不能增加或减少元素,但是可以用集合的思想操作数组,可以用其它集合方法
- 基本数据类型的数组转换成集合,会将整个数组当做一个对象转换;将数组转换成集合,必须是引用数据类型
toArray: 将集合转成数组
若数组的长度 <= 集合的size,转换后的数组长度=集合的size
若数组长度 > 集合的size,分配数组的长度=指定长度
Day017(Set)
Set集合无索引,不可重复,无序(存取不一致)
HashSet
多线程
线程池
使用线程池管理线程好处:
使用线程池可以重复利用已有的线程继续执行任务,避免线程在创建和销毁时造成的损耗
由于没有线程创建和销毁时的损耗,可以提高系统响应速度
通过线程可以对线程进行合理的管理,根据系统的承受能力调整可运行的线程数量大小
线程池工作原理
线程池的分类
ThreadPoolExecutor
newCacheThreadPool构造方法不带线程池容量,最大容量为
Integer.MAX_VALUEnewFixedThreadPool构造方法中需要设定线程池容量
newSingleThreadPool单个线程
ScheduledThreadPoolExecutor
newSingleThreadScheduledExecutornewScheduledThreadPool
ForkJoinPool
newWorkStealingPool
线程池的生命周期
RUNNING –> SHUTDOWN –> TIDYING –> TERMINATED
或:
RUNNING –> STOP –> TIDYING –> TERMINATED
RUNNING: 能接受新提交的任务,并能处理阻塞队列中的任务
SHUTDOWN: 关闭状态,不再接受新提交的任务,但可以继续处理阻塞队列中以保存的任务
STOP: 不能接受新任务也不处理队列中的任务,会中断正在处理任务的线程
TIDYING: 如果所有的任务都已经终止了,workerCount(有效线程数)为0,线程池进入该状态后会调用terminated()方法进入TERMINATED状态
TERMINATED: 在terminated()方法执行完后进入该状态,默认terminated()方法中什么也没有做
ThreadPoolExecutor参数解析
线程池最终调用的都是ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)方法
corePoolSize核心线程池数量
maximumPoolSizekeepAliveTimeunitworkQueue